The Girl From Mars

- Group
- Member
- Posts
- 8,690
- Status
- Online
|
|
Linguaggio macchina
Intro
Oggigiorno siamo abituati a usare linguaggi di programmazione cosiddetti di alto livello. Ma cosa vuol dire?
Vuol dire che il programmatore traduce lo pseudocodice in un linguaggio di programmazione di alto livello, ovvero un linguaggio tecnico e univoco ma pur sempre vicino alla sfera umana, confidando che poi qualcun altro lo converta in un linguaggio di basso livello, ovvero un linguaggio che la macchina possa elaborare. Ma questo qualcun altro chi è? è un interprete. Eh già, un interprete, ovvero un software capace di interpretare un linguaggio vicino all’umana comprensione, seppur tecnico, e convertirlo in un linguaggio comprensibile alla macchina, ovvero basato sull’unica cosa che la macchina discerne: il sistema binario del vero-falso.
Questo interprete è comunemente noto col nome di compilatore, i primi compilatori risalgono agli anni ’50 del secolo scorso, il primissimo fu programmato da una donna: Grace Murray Hopper, alla quale si deve l’idea stessa di compilatore, lo sviluppo del primo compilatore, l’A-0 System nel 1951, e il termine bug col quale oggigiorno sono universalmente noti i gli errori nel software che portano ad arresti anomali o a malfunzionamenti.
Super Grace!
Ora sorge spontanea la domanda: come si programmava prima dei compilatori? In linguaggio macchina. Ovvero ci si sobbarcava l’onere di scrivere il codice in un linguaggio comprensibile alla macchina, cioè in sequenze di vero-falso, senza praticamente alcun tipo di intermediazione. Era difficile? Sì. Però era l’unico modo e i pionieri dell’informatica facevano così.
Ma così come? Vediamolo insieme in queste pillole di linguaggio macchina.
Architettura
La prima cosa da fare è conoscere il processore, ovvero l’esecutore del programma, perché non essendoci alcun intermediario tra la macchina e l'uomo sarà quest’ultimo a doversi sobbarcare l’onere (e il divertimento!) di scrivere nell’unico linguaggio che la macchina comprende: il linguaggio macchina.
Ogni processore ha la sua specifica architettura, ma ci sono degli elementi comuni che ne rappresentano le caratteristiche di base. L’architettura è l'insieme dei criteri di progetto del dispositivo in questione, dal più piccolo circuito integrato al più complesso dei calcolatori elettronici. Nel caso delle CPU (Central processing Unit), acronimo inglese di processore centrale o unità centrale di elaborazione, l’architettura comprende i seguenti elementi principali:
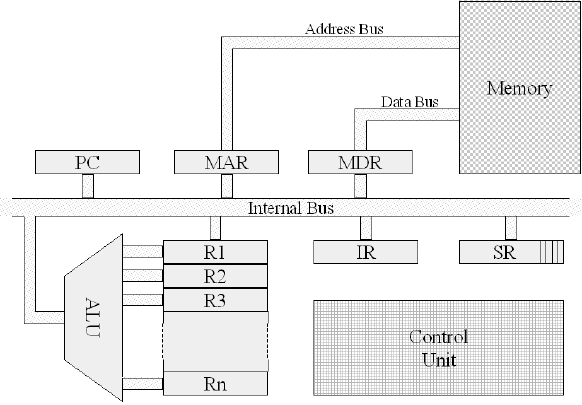
- La CU - Control Unit - è l’unità di controllo e ha il compito di coordinare tutte le azioni necessarie per l'esecuzione delle varie istruzioni.
- L’ALU - Arithmetic-Logic Unit - è l’unità aritmetico-logica e, nell’ambito dell’informatica, è la parte di CPU preposta all’esecuzione delle operazioni aritmetico-logiche. Aritmetica e logica di basso livello meriterebbero ciascuna dei capitoli a parte…
- I registri del processore (o interni):
- per memorizzare i dati da elaborare e i risultati delle elaborazioni della ALU: i cosiddetti registri generali R1…Rn;
- per memorizzare lo stato di esecuzione del programma: il PC o program counter, l’IR o instruction register, l’SR o status register;
- per memorizzare gli indirizzi di dati da elaborare e delle istruzioni da eseguire: il MAR o memory address register e l’MDR o memory data register.
- La memoria contiene un numero in genere molto elevato di registri, posizioni o celle nelle quali vengono memorizzati i dati e le istruzioni di un programma.
- I bus di trasporto dati e indirizzi di memoria: il Data Bus e l’Address Bus.
A questo punto abbiamo le basi per poter parlare dell’insieme di istruzioni del linguaggio macchina.
Istruzioni
L’insieme di istruzioni macchina è, in informatica ed elettronica, l’insieme delle istruzioni di basso livello che l’architettura del calcolatore offre al programmatore. Dunque l’insieme, o set, di istruzioni dipende dall’architettura e per questo viene chiamato ISA, acronimo inglese di instruction set architecture.
L’instruction set è di fatto l’insieme di istruzioni base che il processore può eseguire e che costituiscono il suo specifico linguaggio macchina. Dunque un compilatore dovrà tradurre le istruzioni del linguaggio di alto livello in quello specifico linguaggio macchina, altrimenti quel programma non sarà eseguibile su quel processore.
Il linguaggio macchina è scritto in codice binario. Ogni istruzione macchina è una combinazione di una o più opcode, ovvero operazioni (dall’accorpamento delle due parole inglesi operation code: codice operazione).
L’ISA di una CPU specifica quindi l’insieme delle opcode eseguibili da quel processore centrale.
Assembly
Il linguaggio assembly costituisce l’ISA (Instruction Set Architecture) di un processore.
L’assembly è un linguaggio di programmazione di basso livello che usa codici mnemonici per rappresentare linguaggio macchina. Ciò a vantaggio della leggibilità del codice da parte del programmatore, che può quindi ignorare il formato binario del linguaggio macchina e scrivere il suo codice usando, al posto delle opcode, la forma mnemonica.
La forma mnemonica permette di avere delle parole chiave per indicare le operazioni, ad esempio ADD per le somme o MOV per gli spostamenti. Permette inoltre di usare una base numerica più comoda per la scrittura di dati e indirizzi, solitamente l’esadecimale, e delle stringhe di testo come identificatori. Insomma la forma mnemonica dà al programmatore la possibilità di pensare in linguaggio macchina. Bello no?
Sebbene l’assembly risulti decisamente più leggibile del linguaggio macchina, mantiene con questo un totale isomorfismo. Va detto esplicitamente che, per il fatto di non essere scritto in linguaggio macchina, non può essere eseguito direttamente dal processore. Per essere eseguito deve essere tradotto ed esiste un apposito compilatore che lo fa e che prende il nome di assembler, ovvero l’assemblatore.
Esempio
Vediamo un esempio di programma Hello world in assembly Intel x86 con sintassi Intel (sfrutta le chiamate al sistema operativo DOS).
MODEL SMALL
STACK 100H
.DATA
HW DB "hello, world", 13, 10, '$'
.CODE
.STARTUP
MOV AX, @data
MOV DS, AX
MOV DX, OFFSET HW
MOV AH, 09H
INT 21H
MOV AX, 4C00H
INT 21H
END
E vediamo anche come la CPU esegue l’istruzione “MOV R1, D”. Ovvero lo spostamento del contenuto del registro R1 all’indirizzo di memoria D. Così da rendersi conto di quante operazioni macchina ci siano dietro ogni singola istruzione, anche la più semplice.
I passi necessari ad eseguire questa istruzione sono:- PC → MAR
- Inc(PC)
- Memory Read
- MDR → IR
- PC → MAR
- Inc(PC)
- Memory Read
- MDR → MAR
- R1 → MDR
- Memory Write
Analizziamone nel dettaglio il significato. Trovandoci all'inizio della fase di fetch (cioè la lettura dell’opcode), bisogna prelevare l'istruzione dalla memoria: essa, per definizione, è contenuta all'indirizzo puntato dal registro PC.
Il passo 1 copia il contenuto del PC nel MAR in modo da preparare la memoria ad un accesso alla giusta posizione. Il passo 2, in maniera del tutto generale, incrementa il PC in modo che esso punti alla posizione di memoria successiva, essendo questa la posizione da leggere nel seguito con la maggiore probabilità. Il passo 3 ordina alla memoria di scrivere sul Data Bus e, contemporaneamente, al MDR di leggere dal Data Bus. In seguito a questa operazione il MDR conterrà la prima parte dell'istruzione da eseguire. Essa, per essere interpretata, deve comunque essere trasferita nel IR. Questo avviene al passo 4. Una volta che l'istruzione è stata interpretata, l'unità di controllo “capisce” che l'istruzione è stata prelevata solo parzialmente e bisogna prelevarne un altro frammento. Qui la fase di fetch termina ed inizia la fase di preparazione degli operandi. Nel passo 5, di nuovo il PC viene copiato nel MAR per permettere un nuovo accesso alla memoria; immediatamente dopo, nel passo 6, viene nuovamente incrementato così da farlo puntare alla successiva istruzione, quella che verrà prelevata ed eseguita durante il ciclo successivo. Nel passo 7 la memoria viene letta e l'indirizzo D viene copiato nel MDR. Qui termina anche la fase di preparazione degli operandi ed inizia la fase di esecuzione vera e propria dell'istruzione. Dal momento che la scrittura deve avvenire proprio all'indirizzo ora contenuto nel MDR, questo viene copiato nel passo 8 sul MAR. Nel passo 9 il contenuto del registro R1 viene copiato nel MDR e infine da qui, nel passo 10, viene copiato in memoria alla giusta posizione attraverso un'operazione di scrittura. Termina così anche la fase di esecuzione. A questo punto il PC punta alla successiva istruzione da eseguire, ed una nuova fase di fetch può avere inizio.
Conclusioni
Questa è una piccola introduzione al meraviglioso mondo del linguaggio macchina. Spero vi sia piaciuta 
Edited by Weavy - 8/2/2022, 21:45
|
|

 .
.